Building Microservices - Designing Fine-Grained Systems23rd of April 2017Launching myself into the preface of this book by Sam Newman, the basic premise immediately becomes clear, as he explains Micro Services as an architectural approach (on an application level) to help a company deliver software faster. Although the common census in the IT world is to not invent the hot water over and over, the fact that the fundamental way of software development before Micro Services inhibits easy change of a system. As a side effect of this new paradigm, the author also promises the adapter of this architectural style improved scaling, increased autonomy of individual development teams, and the easier adoption of new technologies. He also proposes to elaborate on the different difficulties and risks associated with a switch to the paradigm, and how to best tackle these. As this book was published by O’Reilly, I started reading it expecting a very technological essay on how Micro Services could be developed, and with the preface, the author more or less confirms my “suspicions” on where this book will take the reader. Honesty right off the bat is the easiest way not to disappoint the reader with unfulfilled promises and missing answers to questions he might have. However, the author does stay on the level of design, never venturing into such detail of actual lines of code. He instead limits himself to giving suggestions on frameworks and technologies to use. |
 |
The first chapter deals with the global concepts that will become the topics for the next chapters of the book. It starts with the definition of Micro Services: They are small, autonomous services that work together. Meaning:
To pinpoint what is small, does not seem feasible, although the author states that they need to be [small enough and no smaller], indicating that most developers can sense when a code base has become too big, and thus warrants a split of the code. In monolithic systems, this translates to the level of cohesion that is wanted, or as the Single Responsibility Principle (Robert C. Martin) states: “Gather together those things that change for the same reason, and separate those things that change for different reasons”. The smaller the service, the more you maximize the benefits and downsides of such an architecture, and is in such an architectural balancing act.
The autonomy part means we consider each service a separate entity. Each service needs to be able to change independently and we should be able to deploy each of them separately without a need for the consumers to change. If this is not possible, most of the benefits of this architectural paradigm disappear. This requires a lot of thought upfront during the design phase to achieve this decoupling (much like contract-first design in classic SOA).
One of the main purposes of the book is to highlight the key benefits over the course of the next chapters. These benefits are:
- Technology Heterogeneity: Micro Services allow to use different technologies side by side, and to adopt new technologies more quickly into the application landscape.
- Resilience: The ability to build systems that can handle total failure of a service and that degrade functionality accordingly. It is important to point out that a highly distributed system such as a Micro Services architecture introduces new types of failure to deal with, as Micro Services clearly goes against such principles known in mechanics as “The greater the number of moving parts, the greater the amount of energy lost to heat by friction between those parts.”
- Scaling: As the compartmentalization is maximized, the scaling can be performed only on those services needing it, allowing for a more pragmatic and efficient use of hardware.
- Ease of Deployment: The ability to deploy a single service independent of the rest of the system. This allows for quicker and more frequent deployment as well as improves oiur ability to pinpoint the source of a possible problem.
- Organizational Alignment: Micro services allow to better align the application landscape to the organizational structure, so that the number of people working on a code base in parallel is minimized.
- Composability: The architecture opens up opportunities for reuse of functionality. This is a point on which I certainly do not agree with the author (see previous article). In my opinion it should even reduce the level of reuse.
- Optimizing for Replacability: With the “smallness” of the components in the application landscape, the cost to replace it entirely also becomes lower.
Looking at previous design attempts to achieve these benefits, the following are highlighted in the chapter: Shared Libraries and Modular Decomposition (what I call a Component Based Architecture). Shared Libraries miss true technology heterogeneity and the ease with which to independently scale parts of the system are severely diminished. Modular Decomposition (such as for example Java’s OSGI) lack any mechanism to manage to lifecycle within the language itself, rather leaving it to the developer to implement such module isolation. The author does point out that, technically, it should be possible to develop well-factored, independent modules within a single monolith process, but in reality this simply does not seem to happen. However, Micro Services are no silver bullet. It comes with its proper strengths, but also weaknesses, and both are elaborated in this book.
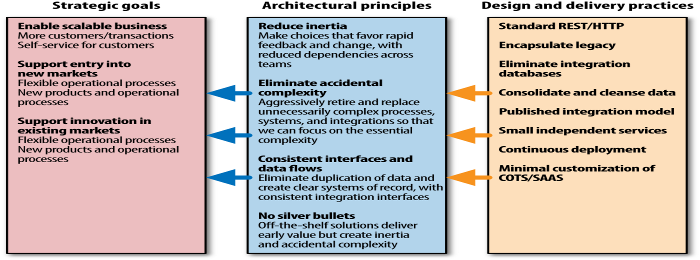
The second chapter of the book deals with the definition of what an architect is in terms of IT projects. As requirements shift more easily than in other industry branches, even after a product is put into production, the architect needs to react and adapt during the entire lifecycle of the product, coining the term evolutionary architect. The author compares an IT architect more to a town planner than to a building architect, and I found this to be an apt comparison. The architect needs to employ a principles approach to be successful in his mission, a framework to making decisions about the trade-offs inherent to IT solutions and projects. The approach is put up in three levels: Strategic Goals (most probably not even technology related), Principles (rules put into place to abide by these goals), and Practices (practical guidelines to implement the principles).
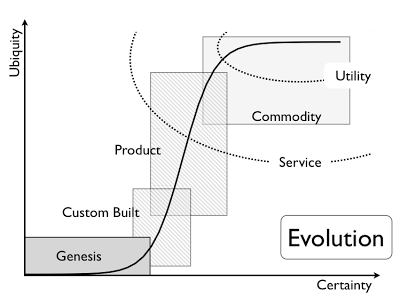
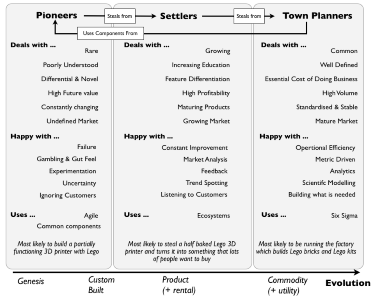
I do wonder when a term such as “town planner” is used in IT literature, whether it is a wink to Simon Wardley’s views on commoditization of ideas. When back in 2012, he postulated his Value Chain Mapping as seen below where there is an evolution for each idea or product to evolve from its conception (or genesis) to a full-blown commodity. Depending on when companies hop aboard the hype train, they are either pioneers (getting in on the action from the very beginning), or settlers (turning prototypes into largely accepted products) or town planners (pushing it into economies of scale). A quick Google search teaches me that I am not the first to make this link, as evidenced by this blog over at OFBIZian.
The main trade-off in a Micro Services paradigm is the variability in the total solution. The architecture should ensure the manageability of the system and thus should determine which characteristics make up a proper service. This is also a way to make sure that one bad service does not destabilize an entire solution or system (resilience). Some of these characteristics are common across all solutions:
- Monitoring: a coherent, cross-services view of the system health is needed for manageability.
- Interface Technologies: a small number of defined interface technologies helps when integrating new consumers of the service. (going against the benefit of Technology Heterogeneity here, but it’s a trade-off to consider)
- Architectural Safety: Services are to shield themselves from unhealthy service calls downstream. This is directly influencing the fragility of the system.
A final topic that is mentioned in this chapter is the role of the architect in governance. The author starts from the COBIT definition:
The architect should not only provide a set of principles (matching the strategic goals) to guide development, they also need to make sure these principles do not make development overly difficult or frustrating, and keep it with current technologies, and know when to make the right trade-offs. However, governance is a group activity which should be led by the architect. But governance can also be facilitated through code, either by using exemplars, or by using tailored service templates. As I think that example code is always useful, for me the use of tailored service templates usually also adds to frustrations of the developer, as he could feel he is limited in his creativity and reduced to a coder monkey.
Chapter 3 dives into how to model a proper service. The aim for each service is to take into account two principles: Loose coupling and high cohesion. We want to make each service to be changeable without affecting other services by picking the proper integration style and limit the number of different types of calls between services. The chattier the service, the more likely it is tightly coupled with others. High cohesion means grouping related behavior together so that when we do need to change the behavior, the change is only needed in one place. This inevitably brings us to the concept of the bounded context, as described in Eric Evans’s book Domain-Driven Design: Tackling Complexity in the Heart of Software.
In short, the bounded context is matched to a Micro Service: A service needs to match with the boundaries of a context/responsibility, and should only offer a single explicit interface determining what to share with other services (also called the shared model in DDD). The main focus should not be on what data is shared by the service, but rather what capabilities its context provides to the rest of the domain. Evidently, once such a bounded context is determined, nothing prevents it from being divided up into bounded contexts of is own. Such a nested approach to Micro Service design is often preferable to a full separation approach from the get go. At the very least it vastly simplifies testing the new services.
Reading through the chapter on integration, there are several options that the author pits against each other: Synchronous versus asynchronous, orchestration versus choreography, REST versus SOAP. Suffice it to say that although he claims all choices have merit, he strongly favors asynchronous (preferably event-based correlation) choreographed REST services over the other options. I have some doubts about such a bold statement. He offers some insights on how to avoid breaking the shared model by looking for the ideal integration technology: keep your APIs technology-agnostic, make the service simple for the consumers, and hide internal implementation detail. Not the easiest of tenets to adhere to, especially the first one: Even REST imposes some technology-related restrictions. But it is clear why that based on these tenets, the author will not endorse either the Shared Database model (claiming you cannot expose sharing behavior this way [except when you use PL/SQL stored procedures to insert/update data??]) or Remote Procedure Calls (which only has the virtue of being slightly better than the Shared Database Model).
The last integration topic of the chapter is how to tackle versioning. Here the suggestions are straight-forward and make a lot of sense:
- Defer breaking changes as long as possible (citing Martin Fowler’s Tolerant Reader pattern as an example).
- Catch breaking changes early.
- Use semantic versioning (as developers have always done since the advent of source control systems).
- Let different endpoints coexist (for example adding version numbers to the endpoints).
- Use multiple concurrent service versions.
- UI Fragment Composition: Letting the service provide (part of) the user interface.
- Backends for Frontends: To reduce the chattiness of services we want to use API gateways that aggregate calls to different Micro Services (much like orchestration/task services in a classic SOA paradigm).
Service design is nice when there is a green field to be built upon, but most enterprises already have monolithic architectures in place, so chapter 5 explores how to split these monoliths into several different Micro Services. It references Michael Feathers’ book Working Effectively with Legacy Code for the concept of the seam: a portion of the code that can be treated in isolation and worked on without impacting the rest of the codebase. The previously discussed bounded context makes for an excellent seam, as we want our codebase to represent our organization (and its domains). To determine which seams to prioritize, a few criteria come to mind: the pace of change (how often does the code change), the team structure (how are the teams working on this seam structured), security (are all data encapsulated by this seam the same level of sensitivity?) and the technology used.
To untangle the Shared Database pattern into micro services, we can start with the common practice of using an ORM- or repository layer (think Hibernate and the like). But the author would like us to go further than that. Breaking the Foreign Key Relationships in the database when they cross the boundary of a bounded context, and putting this as a constraint into the encapsulating service, as well as extracting shared static data from the database into a property file (or even a proper service of its own if warranted). Shared mutable data and shared tables each point to a lack of a certain concept in the data, necessitating the introduction of such a concept as a new service. The possible resulting degradation of the transactional boundary can be caught either by a distributed transaction (not the greatest working concept in my experience, especially when queues are involved) or compensating transactions. The author admits all of these options add complexity and reduce performance, but considers the upsides outweigh the downsides.
For reporting databases (filled with a periodic sync), which typically group together data from across multiple domains in an organization, there is a need for more specific solution, as even here the author wishes to prevent the crossing of boundaries. We could consider provisioning these reporting databases with service calls, but the sheer volume of data being passed to them usually makes this inadvisable. For these cases, a data pump can be installed to pump the relevant data from the domain to the reporting database, keeping the shared model between them firmly under the management of the team responsible for the domain and not the business intelligence development team. One can even consider an event data pump which is triggered to push the changed data each time the source has an insert, update or delete within its data set. More info on this type of database refactoring can be found in Scott J. Ambler's book "Refactoring Databases: Evolutionary Database Design".
The next chapter is all about deployment, or more specifically continuous integration and deployment. It gives a brief look into what continuous integration is, but I’m not going to review that here. In order to make CI work for Micro Services, there are several possibilities as shown in the diagrams below (taken from the book).
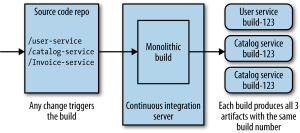
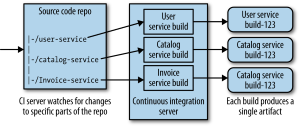
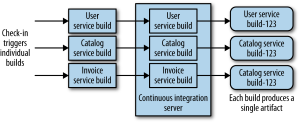
The first diagram shows a single source repository for all services as well as a monolithic build process. Evidently, this has the drawback that any change in any service will trigger a rebuild and revalidation of all services generating multiple artifacts to deploy. This is a model that goes hand in hand with lock-step (or corporate fixed) releases, and as such degrades the benefit of frequent (and independent) deployment of services. It will also impact cycle times, and can easily make that code from different services becomes more tightly coupled. This is mitigated partly with the second model where one code base maps onto different build processes, but the preferred CI model is where independent source repos trigger independent build processes. Ideally, these build processes become build pipelines with continuous delivery thrown in the mix. A proposed pipeline would be the one shown in the illustration below.

One of the issues with the technology heterogeneity advantage of Micro Services is that the need for platform-specific artifacts arises. One way to avoid this problem is to create artifacts that are native to the underlying operating system (such as for example MSI for Windows). Another is to produce custom images to be deployed by tools such as Chef or Puppet, which we can use to deploy the latest version of a service on a running instance of our custom image. Or we can simply produce these custom images as the artifact of our build process. Another possible problem that is averted in this way is the issue of configuration drift where the configuration of our image after a time no longer matches the configuration in the source control repository.
The question to group services or not per build process can also be asked when doing the deployment to hosts. Multiple services per host might seem a good idea since most of the time the overhead cost of the infrastructure team is determined by the number of hosts it has to manage. There is also a higher cost associated with multiple hosts, since even with virtualization there is an overhead cost to more virtual machines. Downsides on the multiple services per host model are increased difficulty in monitoring on the granularity of the individual service. Independent deployment of individual services as well as scaling also becomes more difficult as services might require different (or even contradictory) configuration of the host. If the services deployed on a same host are under the auspices of different teams, it certainly inhibits the autonomy of these teams.
A single host per service has its benefits: no more single point of failure, an easier scaling of individual services, and security measures tailored to the needs of the service. It also allows us the deployment of images as discussed earlier. Certainly the overhead through management needed for these hosts increases unless we automate the deployment. Ideally we realize these hosts through standard virtualization (for example VMWare) or through container-based virtualization (for example Docker). Beware: The key to automated deployment is a uniform interface to deploy any given service.
Something not mentioned in the book, but which is a suggested best practice by Oracle for a classic SOA, is that the deployment mechanism should also be idempotent in all occasions. It is important to limit the amount of scenarios with a need for human intervention. This means making the deployment robust enough to handle consecutive deployments of the same service (and service version) without difference in result. When the deployment mechanism produces an error early on in the run, the automated deployment mechanism should be able to deal with most of these cases. For example: undeploying a previous version of the service.
When regarding automated testing the book forms its view on them by using the categorization system of Brian Marick in the book “Agile Testing - A Practical Guide for Testers and Agile Teams”, as well as test scopes defined by Mike Cohn’s Test Pyramid from “Succeeding with Agile - Software Development Using Scrum”. In order to understand the terms used on their illustrations below, the author wishes to make them clear so no misinterpretation can happen, as terms like service tend to mean different things in different contexts.
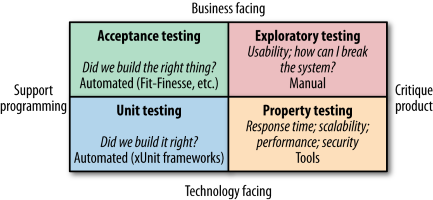
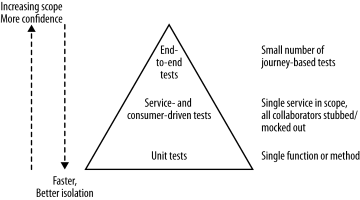
Unit tests are pretty straightforward in the IT industry and are generally generated as the side product of test-driven design. Service tests are aimed at bypassing the user interface and accessing the services (in this case the Micro Services) directly in order to test them. End-to-end Tests span the entire system, usually driven through a GUI or the mimicking of such a GUI. Higher up the Test Pyramid, the test scope increases together with the confidence in the functional requirements being met. However, as feedback cycle time increases from longer test runs and the increased number of components involved makes it harder to determine what causes a test failure.
When looking at the Test Pyramid a good rule of thumb for determining the quantity of tests to be written, is that you want an order of magnitude more tests the deeper on the pyramid you are. As for the use of mocks or stubs, this is another tradeoff between facilitation of testing and in-depth testing. This tradeoff is elaborated more fully in “ Growing Object-Oriented Software, Guided by Tests” by Steve Freeman and Nat Pryce. But mock or stub, you always want to put in at least some logic to make it a bit smarter, either by ensuring the proper return or in the case of mocks even fake connectivity. When getting to end-to-end testing however, we do want to take into consideration aggregating our build pipelines into a single step instead of reproducing all end-to-end tests in each pipeline. It is imperative however that the deployment of the services remain independent in order not to create a metaversion for these “cooperating” services and slip back into the monolith deployment issues.
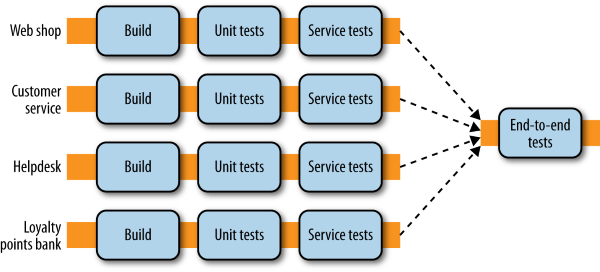
There are many disadvantages associated with end-to-end testing that makes us want to limit the number of tests we write. First and foremost, they can be brittle. As the test scope increases, so does the amount of moving parts. Hence, when a problem arises in the test, it is not as easy as in other tests to point to the cause. They can also be flaky as sometimes tests will fail that succeed at other times without changing them. In these cases, an effort needs to be made to remove these cases and replace them with more reliable test scenarios. There is also the question of who needs to write these tests as the components used might be owned by different teams. And a dedicated team to write these tests is calamitous if the development team becomes more and more detached from the tests for its code. For these cases a joint ownership is the lesser of two evils. And as these test cases take long times to execute, a problem with them might take a while to get fixed, causing a pile-up of changes in upstream development, and increasing the difficulty of fixing it.
The answer to these disadvantages is to create test journeys. These are a small number of core scenarios for the whole system. This also means that any functionality not covered in the journey should be handled in a smaller test scope. We should also employ consumer-driven contracts. This means that the consumers of our service should stipulate their expectations of the service’s behavior to be captured in one or more test cases (usually service tests). One option is to move the excess end-to-end journeys away from testing to monitoring scripts for production systems. Here the choice is to prefer Mean Time to Repair (MTTR) over Mean Time between Failures (MTBF) and to shift more resources into monitoring than into testing. For this approach, more specialized deployment strategies are needed.
These deployment strategies all depend on the ability to redirect traffic in a production environment, so that for example a smoke test suite can be hurled against a freshly deployed service in order to gauge its functionality and performance in production. A typical approach is a blue/green deployment for these smoke tests where both versions of the service coexist in production, but the smoke test traffic is routed to the new version in order to test it. When the service works as expected, all traffic can then be routed to the new service. Similar to this is a Canary Release where a limited amount of production calls is routed to the new service version in order to test its correctness.
When the approach to test in production is chosen, of just in general for any setup of SOA paradigms, monitoring is of key importance. With Micro Services, as elaborated in chapter 8, this necessity is rendered more complicated. The more moving parts, the more it becomes difficult to monitor them consistently. The main idea is to monitor the small things, and use aggregation to get the bigger picture.
Depending on how many servers are running the same service, the monitoring approach is slightly different. When using the “single service on a single host” setup, the first thing to monitor is the host itself (CPU, memory…). When a problem arises, the logs of the servers should preferable help use locate the problem. It is also a good idea to monitor the service itself, such as for example the response time of the service. When using the “single service on multiple hosts” setup, we need to monitor all the same things, but for the server logs, a need arises to have an aggregated view. This can be as simple as the logs of the load balancer server.
When multiple services running on multiple hosts are collaborating, this need for an aggregated view becomes crucial. In order to get this unified view on the logs and to do analysis on them, such tools as Logstash and Kibana exist. Metrics tracking across multiple services, especially in an environment where we are constantly provisioning new instances of said services pose additional complications. Whenever a new instance comes online, it should grant easy access to its metrics. The aggregations of these metrics should be encompassing all instances of all collaborating services, as well as all instances of the service, as well as a single instance of the service. Each of these levels of metrics aggregation is made possible by the proper application of metadata. This information gives the added benefit of insight into the usage pattern, which we can then in term employ to match the infrastructure to the need (just enough). This renders the system more cost effective and more responsive.
For these aggregations to be possible, a good design practice is to let services expose basic metrics such as response times and error rates themselves. They can also be set up to provide metrics on usage so that their need can be assessed and thus make them more attuned to how the users are using the system and improve them accordingly. Since we can never predict which metrics will be useful in which situation, the more metrics exposed, the more the service will be prepared to support future operations. The introduction of a correlation ID to be passed via a context to each collaborating service in order to reconstruct the flow of service calls is also available in our design toolbox.
Another interesting metric is the fact whether the system as a whole is working. Since the number of moving parts with the introduction of Micro Services can drastically increase, so can the sheer amount of logging available make it harder to determine this. For such a need, the synthetic transaction is introduced. This way we set up a system of semantic monitoring. By introducing fake data to be sent across the system (and to be identified by the individual components as such), this fake data can be tracked across these components to assess their individual health and the overall health of the system. A caveat on this: Make sure that no unforeseen side effects are accidentally triggered by this approach.
When considering what to write to the various logs, the key is making it easy for those reading them to do their job. For this, standardization of how you write in these logs goes a long way. We need to make a distinction though on to what people need to react immediately, and what data they need when analyzing (drill down). An interesting resource is “Information Dashboard Design: Displaying Data for At-a-Glance Monitoring” by Stephen Few. So for data in the log files, the following points are to be taken into consideration:
- What the interested parties need to know right now (alerting)
- What they might want later (easy access)
- How they like to consume these types of data (making it easy)
The chapter on security was a bit of a letdown for me. Having working in-depth with security issues on past projects, the topic of security (although the focus of a chapter of its own) didn’t really go much into detail. While it points out some problems occurring with service oriented architectures, no real solutions were offered on how to tackle them. A redeeming quality is that it does make the distinction between data in transit and data at rest. The start of the chapter briefly dives into the first two parts of the Triple-A of Security: Authentication, Authorization, administration, and Audit. Indeed, the Triple-A has four parts, much like Alexandre Dumas’ book “The Three Musketeers” has four antagonists. ☺

The Single Sign-On implementation (SSO) is positioned as an enterprise standard (rightly so). And the most common technique is said to be SAML (via SOAP), and to a lesser degree OpenID Connect (via REST). To avoid each service to perform the authentication handshake, the book offers the possibility of using an SSO gateway to act as a proxy and handle the necessary security steps. The difficulties with such gateways are that is it harder to pass information about principals to downstream services, and that it becomes harder to set up production-like environments. There is also the issue that it may give a false sense of security if this part of the solution is the only security-enforcing component.
The author also makes a case for favoring coarse-grained roles, modeled on how your organization works. His claim is that fine-grained roles tend to lead to an explosion of roles that become increasingly harder to manage. This is indeed the case, as it was with classic SOA as well. Another approach is to forego Role Based Access Control (RBAC) and instead go for Attribute Based Access Control (ABAC) and its use of security policies. For service-to-service authentication (data in motion) and authorization he offers some possibilities (trust circles, HTTP basic authentication, SAML/OpenID Connect, Client Certificates, HMAC over HTTP, API keys…), but doesn’t really delve too much into their application on Micro Services. For data in rest, he suggests to stick with what is well-known: encryption with proven encryption algorithms (such as AES-256), not storing unencrypted data anywhere, backup encryption… And for the security in depth, the standard stuff: Firewalls, Logging, Intrusion Detection (and Prevention) Systems, Network Segregation, OS patching…
One piece of advice he gives at the end of the chapter is to be frugal with data. From the German privacy legislation, he takes the word Datensparsamkeit, or to only store as much information as is absolutely necessary to fulfill business operations or regulatory compliance and forego the rest. This is a concept that will also become more prominent with the introduction of Europe’s General Data Protection Regulation (GDPR).
Conway’s Law rears its head in chapter 10. Martin Fowler was also big on this in his signature piece on Micro Services, and I gave my views on this as well in a previous article. Similar to Martin Fowler’s statements, the author also takes it as a point of departure for the organizational changes accompanying the transition to the Micro Services paradigm. Amazon’s two-pizza teams and Netflix are hailed as examples of how to pair a team (of small size) to the bounded contexts at the basis of a service landscape. Basically, the teams need to be small and independent in order to optimize for speed of development. The author also alludes to a reverse Conway where the organization is adapted to the services, but hasn’t seen much evidence of this happening. This is however typically what ERP and CRM architectures are geared towards. For example: When buying an SAP ERP system, its idea is to adapt most business processes to the standard processes in SAP and not the other way around.
Small teams allow for fine-grained communication, reducing the cost of coordination drastically. Whenever cost of coordination becomes too high, it has two possible effects: people find ways to reduce it or the code base is no longer changed with any frequency, and large, hard-to-maintain codebases are born. Not only should you keep the team small, but they should also be collocated to suppress any increase of coordination cost in this fashion.
When the teams are small enough, service ownership can be extended to mean complete responsibility for making changes to a service. Service ownership is extended to encompass not only the coding, but also the deploying and maintaining of the service. No more possibility to “throw it over the wall” to the next team. It adds the benefit of increased autonomy of the team to the list of pros. When you are able to match your team structures to the bounded contexts of the services, you gain multiple other benefits:
- The teams will grasp the domain concepts of their service more easily.
- Services within a bounded context are a lot more likely to converse with each other, reducing the difficulties of system design and team coordination.
- A good relationship with all stakeholders of the context is more easily forged.
In case service ownership needs to be shared over multiple teams (the author strongly advises against such a setup), either due to teams being organized per cross-bounded context features, or due to delivery bottlenecks, it is advised to create a type of internal open source model. This means assigning a small group of people considered core committers. They need to be made aware of code changes by other committers and incorporate these into the codebase so that the quality and consistency of the code base within the service is guarded over. They have a custodial responsibility. This gatekeeper model appeals a lot to me, and in my opinion is even a good idea to adopt in other architectural paradigms or governance approaches.A last caveat in this chapter is that of the orphaned service. This is a service of which no team has ownership. This is to be avoided at all costs. Even if the technologies used in the service are no longer mastered by people in the company, a team should always be made accountable (also for finding the proper resources to adapt this service).
The chapter finishes off with a part about the people, and how they should interact within a team. No longer is the coder someone alone on an island, but he needs to be aware of the implications of the decisions made within the team. The author doesn’t really offer any pearls of wisdom on this topic, stating that all team dynamics are in some way or another unique to the situation. The only point of attention he raises is to assess the appetite for change of the company and take this into account. This part of the book, I find, it not very well developed, at least not compared to the technological issues he elaborates on.
Chapter 11 dives into the scaling benefit associated with the architecture, and how to best tackle this autonomous scaling of individual services. The chapter identifies the two reasons for scaling: dealing with failure and performance. It also tries to hand the reader several coping patterns to maximize on this benefit. The first premise is simple: Failure is everywhere. There are many possibilities for failure such as for example networks in distributed computing, which are inherently unreliable. We should accept that the system is going to fail, and plan/design accordingly. This starts with determining how much failure can be tolerated: A reporting system that generates reports once a month has a lower urgency than a production system processing thousands of records every minute. For every system, the following requirements should be determined:
- Response time/Latency: the duration of any operation performed by the system, and what is acceptable.
- Availability: the allowable down times for any given system.
- Durability of Data: The amount of data loss that is acceptable in case of failure.
In order to safeguard these requirements, several architectural safety measures can be applied to limit the ripple effects of any one failure. This can and should even be put to the (regular) test, either through scheduled and recurring disaster recovery exercises, or by such means as Netflix’s army of simians (a set of programs active on their production environment that actively causes failures on a daily basis). These patterns can be categorized as either software patters, hardware patterns, database scaling patterns or caching patterns.
The software patterns discussed in the book are timeouts, circuit breakers and bulkheads. Timeouts are pretty straightforward. Define timeouts for every service. Start with a default timeout for everything, monitor them, and adapt timeouts according to the actual behavior of the service. Circuit breakers monitor downstream services, and when a certain number of failures occur in these, it is activated and automatically starts failing requests to these services without invoking them, only letting some calls through after a certain time to detect whether the downstream services have recovered so that it can deactivate itself. How to implement such a breaker depends heavily on your definition of a failed service call. Ideally, when activated, the incoming requests should be buffered, so that afterwards a replay of them can happen. Bulkheads are analogous with the part of a ship that can be sealed off to protect the rest of the ship in case of catastrophe. This can be by implementing separation of concerns (such as a connection pool for each individual service). This can also be done by load shedding: actively rejecting requests to service to prevent service saturation. While timeouts and circuit breakers help you free up resources in failure situations, bulkheads attempt to prevent a constrained situation from happening.
The go-to solution of scaling for performance is usually the vertical scaling of infrastructure, adding more servers to the mix. However, we must ensure that the software can actually benefit from this addition of resources. This tactic also does little to increase the resilience of the system. This can be achieved by running services on different hosts. However, virtual hosts usually still have shared physical hosts, so there is still a single point of failure. We can further enhance resilience by ensuring services not only run of different virtual hosts, and divide the physical hosts that power these virtual hosts over different racks, possibly even in different data centers. Performance can also be achieved by dividing the load over several instances of services either through load balancing or worker-based systems.
When scaling databases, we see that different types of databases come with different options for scaling, and we need to match these to our needs to ensure we have selected the correct one from the beginning. A tradeoff between availability of service versus durability of data needs to be made in every case. This is put into contrast by what you are trying to scale for: optimization for reads or optimization for writes. Even Command-Query Response Segregation (CQRS) comes with its own set of caching solutions. In the case that many services in your system are read-only, we can opt for either caching of data or by utilizing read replicas. However, the main issue here is how to deal with stale data (being data not yet synchronized with the master data). Scaling for writes to the database is usually done by means of data sharding (using algorithms to determine which target to write to, and algorithms such as for example MongoDB’s MapReduce to query across these shards). However, where sharding scales for writing volume, it does not improve resilience.
Caching is a technique commonly used to enhance performance. It comes in three popular flavors: Client-side, proxy and server-side caching. With client-side caching, the result of a query to the server is cached at the client, and the client determines the strategy for when to use this cached result or fetch a more up to date result from the server. This drastically reduces network time and reduces load on downstream services. The caching of this result can also be done on a proxy between client and server (for example a reverse proxy or Content Delivery Network) and thus the determination when to fetch a fresh result falls to the proxy. The advantage of this approach is that it is transparent for both client and server. The caching responsibility can also be handles server side with tools such as Redis or Memcache, making it transparent for clients and potentially has a better understanding of when to invalidate a cache and fetch a fresh result.
Caching is also possible for other purposes such as for writes (with a write-behind cache flushing to the downstream source at a later time) or caching for resilience as a fallback in case of downstream service failure. However, keep it simple as each introduction of a cache necessitates a strategy on how to deal with stale data and cache invalidation.
Ideally, we have an autoscaling system in place which allows for the fully automated provisioning of virtual hosts and the deployment of services on them. This provisioning could be triggered by well-known trends (for instance repeating tasks such as automatic contract renewals), or it could be reactive to the detection of increased load or instance failure on our system, bringing service instances up and taking them down as needed. Both are very useful when trying to create a cost effective system. But each require a careful analysis of the data available to you.
To determine which tactics to embrace and which to put on the shelf, we can employ the CAP theorem:
Consistency is the characteristic that determines that a service will always give the same answer across multiple nodes. Availability reflects that every service request should get a response. Partition tolerance is the ability to handle the occasional failure in communication between two services.
When an organization starts amassing a plethora of services, it is imperative that a proper overview is retained of what is available. This can be done by service discovery: a mechanism for services to register themselves and indicate that they exist, as well as a way for services to detect what other services are out there that they can use to further their purpose. In case of autoscaling environments where services constantly come up and go down, this becomes even more important. Documenting services is also a possibility where the API’s are described in enough detail to be of use. However, this approach is highly dependent on keeping this documentation up to date. This can be a daunting and even tedious task for most developers.
The final chapter summarizes the key principles of Micro Services in 7 distinct topics:
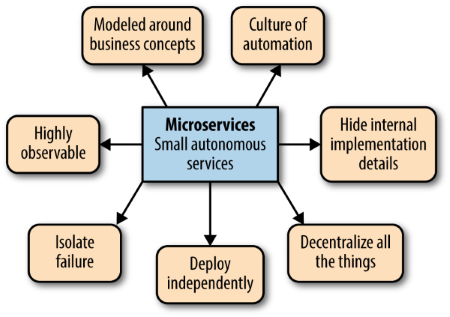
The author also leaves us with some caveats for when not to use Micro Services (a topic which is not addressed enough in the book for my tastes – I want to know up front what possible problems I will get into using any architecture paradigm in order to make a proper pro/con assessment):
- Green field development is tricky since the domain driven design is complicated by the possibility that we do not yet have a proper grasp on the domain.
- Many challenges with Micro Services get worse with scale.
| Review | SOA |