Expert AWS Development -
27th of April 2018 |
 |
The second chapter deals with connecting to existing AWS services (DynamoDB, Kinesis, SQS, and SWF). First off, when loading the code samples available for download with this book, there are already some that use deprecated methods from the newest SDK, so for a book that is a month old when writing this review, this was a bit of a letdown. But the code, low-level as well as document and high level interfacing, still works on the condition that a “Movies” database has been created in your DynamoDB setup prior to running the code. No explanation in the book on how to do this, so I had to peruse the documentation of Amazon AWS itself, and adapt what I read there to code samples, as well as fill it with some data.
System.out.println("Attempting to create table; please wait...");
CreateTableResult table = dynamoDB.createTable(
Arrays.asList(new AttributeDefinition("title", ScalarAttributeType.S),
new AttributeDefinition("year", ScalarAttributeType.N)),
tableName,
Arrays.asList(
new KeySchemaElement("title", KeyType.HASH), // Partition key
new KeySchemaElement("year", KeyType.RANGE)), // Sort key
new ProvisionedThroughput(10L, 10L));
System.out.println("Table status: " + table.getTableDescription().getTableStatus());
System.out.println("Adding a new item...");
final Map infoMap = new HashMap();
infoMap.put("plot", "Nothing happens at all.");
infoMap.put("rating", 0);
PutItemOutcome outcome = table
.putItem(new Item().withPrimaryKey("title", "The Big Lebowski", "year", 2015).withMap("info", infoMap));
System.out.println("PutItem succeeded:\n" + outcome.getPutItemResult());
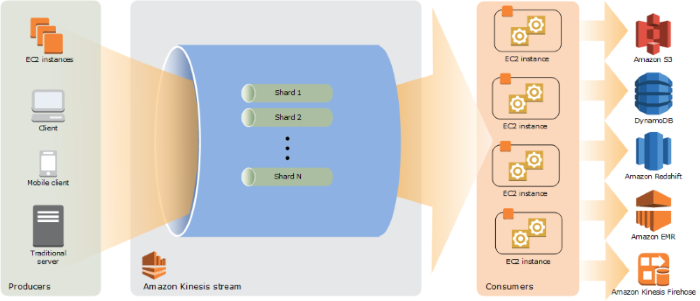
The sample code for the Kinesis manipulations (both Stream and Firehose flavors) are less dependent on previous setup, and are therefore more robust, even if also still using deprecated code. The same experience is had with the Simple Queuing Service (SQS) coding samples. Straightforward, creation, upload of messages, consuming of messages, and destroying the queue to give an overview of how to interact with these services.
When it comes to Simple Workflow (SWF), I am not convinced after running the examples, that this is a worthwhile component to use. It is a glorified state machine that needs to be polled in order to determine where in the workflow your process is currently at. For me, as a state machine it is too complex, with too many restrictions on how many resources can be consumed. Thus, it is better to just build one fit for purpose. As a workflow engine, it is lacking so many capabilities that using a Camunda or Activity setup will almost always be more effective.
The third chapter of the book is an introduction of the concepts used in the fourth and fifth chapter. It defines DevOps as the end-to-end lifecycle of a product built on the business needs and shared goals of an organization. It splits the DevOps processes into Continuous Delivery, Continuous Integration (CI), Continuous Testing and Continuous Deployment (CD). It equates this product lifecycle to the typical Software Development Life Cycle (SLDC), but this is a bit erroneous in my view, since a the SLDC never incorporates operational processes into its phases. SLDC is just a part of Application Lifecycle Management (ALM). It aims to increase the frequency and quality of releases by detecting and fixing software defects in a shorter time, and improving collaboration between teams.
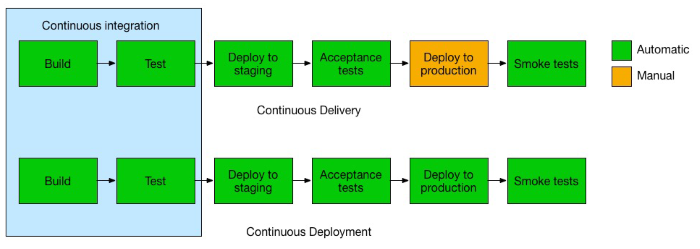
CI is the continuous merging of all code by developers into a main code set, so that other developers and testers have access to this integrated version, maintained in a repository such as SVN or GitHub, as soon as possible. This repository also enables build and deployment automation. Continuous Delivery is the prepping and deploying of this integration code into an environment that can be used for acceptance testing. This reduced the risk of deployment (as it is done more often with smaller chunks of code), allows you to track progress, and enables quicker feedback from end users. Continuous Deployment is an extension of CI, and schedules testing to be done on a clone of the production environment before the code merge takes place in the main branch. This makes it so that deployment on the production environment can happen in an automated fashion, further reducing deployment times. The services available in AWS are described in chapter 4 and 5, and are summarized as follows:
| AWS Tool Name | Capability | Description |
|---|---|---|
| AWS CodeCommit | Version Control | It is used to store source code securely on private Git repositories. |
| AWS CodeBuild | CI/CD | It is used to build and test code with continuous scaling, packaging it for upload into a public Docker Hub or Amazon EC2. |
| AWS CodeDeploy | CI/CD | Automatic deploy (both in-place and blue/green) of AWS services such as EC2 instances or Lambda functions. Supports lifecycle hooks events. |
| AWS CodePipeline | CI/CD | This is a CI/CD Service from AWS, where you can set up a workflow that determines the behavior of your build & deploy. It uses CodeBuild and CodeDeploy to achieve this. |
| AWS CodeStar | CI/CD | Quickly develop, build, and deploy applications using templates (similar to Maven archetypes). |
| AWS X-Ray | Monitoring/Logging | Used to debug and analyze the applications for bugs and performance issues through user request tracing and service maps (between services and resources). |
Chapter 6 deals with the AWS Cognito component, which is a user authentication service with signup and sign-in capabilities for web and mobile applications. The service can be called using the OAuth framework. Once a domain has been configured for your user pool, the Amazon Cognito service automatically provisions a hosted web UI that allows you to add sign-up and sign-in pages to your app. It can authenticate from social IDPs such as Facebook, Google, … as well as use federation services such as Active Directory Federation Services (ADSF) through SAML, OAuth an OpenID. It is compliant with HIPAA-BAA, PCI DSS, SOC 1–3 and ISO 27001.
Chapter 7 describes the architectural concepts for web hosting, comparing the traditional setup (either dedicated or shared) versus cloud hosting with AWS. The main trumps of a cloud web hosting are high performance, scalability reliability, security, and low cost (pay as you need). The main components for such a setup are EC2, Amazon’s Virtual Server service (either with or without Elastic Container Support for Docker usage) and S3 for static content. If we want to add the traditional web application setup with load-balancing, routing, and security, other components such as Elastic Load Balancing, Route 53 and CloudFront can be used.
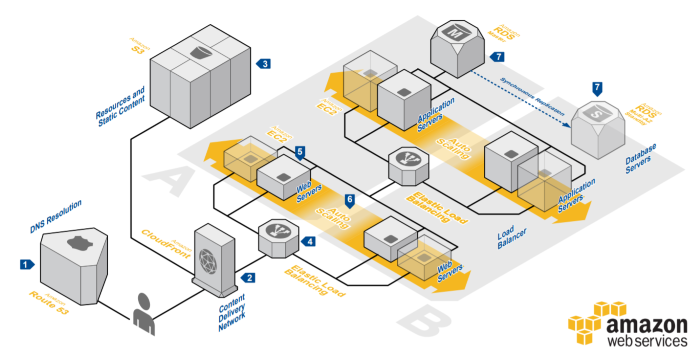
In order to get a feel for which components achieve which goal, Amazon offers guidelines assembled in the Well-Architected Framework, where reference architectures and calculation tools can be found. The framework aims to design proper applications based on 5 pillars, each with an accompanying whitepaper on how to optimize for this type of requirement. The framework aims to help architects mitigate risks, and make informed decisions by making correct tradeoffs between these categories, and generally build applications faster by fast-tracking the design aspect. The main principles all revolve around reducing guesswork, automating as much as possible (tests, deployments, operational tasks…) and testing systems and solutions on production scale environments.

The eighth chapter deals with a traditional setup of an EC2 instance, by using an Amazon Machine Image (AMI) as a template for which type of virtual server you wish to set up, as opposed to the ninth chapter dealing with containerized EC2 instances. The traditional instance is backed up using the Elastic Block Service. The chapter offers some best practices, most of which are common sense, like not using any blacklisted AMI. Some useful tips are to optimize costs by removing any unassociated Elastic IP addresses, and also to verify that the EC2 instances are evenly distributed across multiple Availability Zones in a Region.
You can address any high availability and failover requirements by launching your EC2 instances inside an Auto Scaling Group, defining the minimum and maximum number of instances it can scale between. The load balancing over these groups is done by the Elastic Load Balancing service. It features high availability, distributing load over multiple targets (EC2 instances, IP addresses, containers, availability zones…), health checks to detect unhealthy targets, and operational monitoring. It supports TLS termination, and both layer 4 (TCP) and layer 7 (HTTP, HTTP/2 and HTTPS) load balancing. The service offers three distinct flavors: Application Load Balancing (ALB), Network Load Balancing (NLB), and Classic Load Balancing (CLB) for VPC or in the case of the classic flavor also for EC2-Classic.
| Feature | ALB | NLB | CLB |
|---|---|---|---|
| Protocols | HTTP; HTTPS | TCP | TCP; SSL; HTTP; HTTPS |
| Health Checks | ✓ | ✓ | ✓ |
| CloudWatch Metrics | ✓ | ✓ | ✓ |
| Logging | ✓ | ✓ | ✓ |
| Zonal Fail-over | ✓ | ✓ | ✓ |
| Connection Draining (Deregistration Delay) | ✓ | ✓ | ✓ |
| Load Balancing to Multiple Ports on the Same Instance | ✓ | ✓ | |
| WebSockets | ✓ | ✓ | |
| IP Addresses as Targets | ✓ | ✓ | |
| Load Balancer Deletion Protection | ✓ | ✓ | |
| Path-Based Routing | ✓ | ||
| Host-Based Routing | ✓ | ||
| Native HTTP/2 | ✓ | ||
| Configurable Idle Connection Timeout | ✓ | ✓ | |
| Cross-Zone Load Balancing | ✓ | ✓ | ✓ |
| SSL Offloading | ✓ | ✓ | |
| Server Name Indication (SNI) | ✓ | ||
| Sticky Sessions | ✓ | ✓ | |
| Back-End Server Encryption | ✓ | ✓ | |
| Static IP | ✓ | ||
| Elastic IP Address | ✓ | ||
| Preserve Source IP Address | ✓ |
When deploying in a Docker container, AWS offers the EC2 Container Service to deploy in a Linux-based container. Windows containers are also possible, but offer less possibilities. When deploying such container instances, you need to register the cluster using a container agent. The container-optimized AMI come with this agent pre-installed. This agent together with the connection status will indicate the state of the container using straightforward values:
| Container Instance Status | Connection Status | Description |
|---|---|---|
| ACTIVE | TRUE | Agent has registered the container instance in a cluster. |
| ACTIVE | FALSE | The container instance has been stopped. |
| INACTIVE | FALSE | The container instance has been deregistered or terminated. |
| DRAINING | TRUE | The container instance will not accept any new tasks. Typically, this is set in preparation of an upgrade. |
Amazon ECS clusters are logical groupings of tasks and services. If these are of the EC2 launch type, then the cluster will group the EC2 instances. The tasks can be run manually or be scheduled using either a scheduler in your ELB service, or use a third-party scheduler. When opting for the ELB scheduler, several task placement strategies can be applied, such as “One Task Per Host”, “AZ Balanced Spread” (tasks distributed across Availability Zones and instances), “BinPack” (optimized for CPU or Memory), or even a custom defined strategy.” Each of these tasks follows the lifecycle illustrated below.
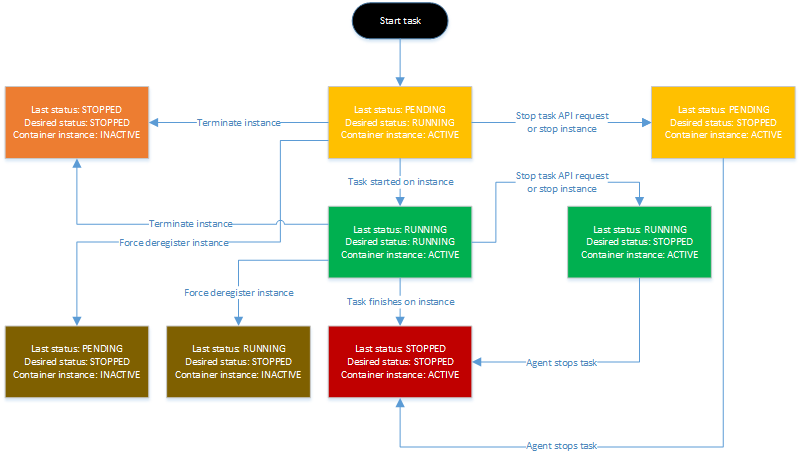
With all these possibilities for web hosting, it is imperative that the total picture of cost is kept under scrutiny, as it might become steep very quickly. Monitoring this cost is assisted by AWS Trusted Advisor, monitoring and adjusting deployments to usage, AWS Simple Monthly Calculator to calculate your transfer costs, and AWS Cost Explorer to visualize the pattern of your spending over time. There are also several options to reducing this cost. One of these options is making use of cost efficient resources. Amazon offers a variety of flexible pricing options: On-Demand instances (pay per hour, no minimum commitment), Reserved instances (reserve for one- or three-year periods at reduced cost), and Spot Instances (bidding on unused EC2 instances). It is also in your best interest to decommission unused resources as quickly as possible, temporarily stop resources that are not needed, and identify and decommission orphaned resources. A third option is to match your resource provisioning to the demand by setting up usage patterns (time-based, demand-based or buffer-based) for new resources.
The tenth and last chapter deals with the Serverless Framework in general and more specific with the Lambda services. It starts off by detailing a few of the characteristics of a Microservices Architecture, but there are better books that detail this, such as “Building Microservices” by Sam Newman. The chapter elaborates a bit on environment variables and dead letter queues, and how to set them up, but further than that it doesn’t really show any Lambda services in action. It also briefly details Lambda@Edge, which is a service that allows you to run code across multiple AWS regions with low latency for the user, and the AWS Serverless Application Model (SAM), which allows you to deploy serverless application.
The chapter elaborates on the Serverless Application Framework as well, detailing benefits of a serverless application as well as benefits of the Serverless Framework. Serverless is a toolkit for deploying and operating serverless applications, not only supporting AWS, but also other players such as the Google Cloud Platform and Microsoft Azure. When a serverless application gives you the benefits of less administration, auto-scaling, pay-per-use and increased velocity, the framework grants its benefits more in the realm of ALM with increased development speed, infrastructure as code, and avoidance of vendor lock-in. It also features many community plugins readily available on GitHub.
In all this book did not really live up to my expectation. It does provide a tour of the most common AWS services, but barely scratches the surface of what is possible with them, and only highlighting how to set up a basic version of these services. Therefore, the Expert part of the title seems misplaced. It also assumes some pieces of code and knowledge to already exist, leaving a novice to the AWS range to sift through the documentation and examples available on Amazon’s AWS website in order to find the missing information.
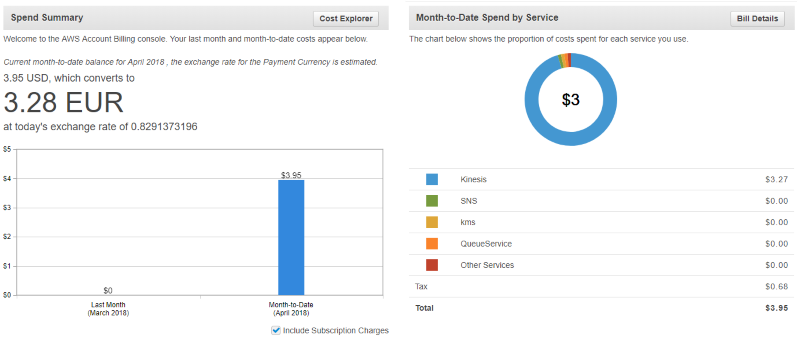
As for the AWS platform as such, it did strike me as rather expensive, since just running these examples in the book, and a bit of experimentation for about a week, already left a tab of about 3.28 Euro. This is generated solely by the Kinesis examples in the book, which don’t really generate that much traffic. I have to wonder whether these Kinesis streams are really so interesting that a company wants to rack up a bill so quickly.
As a coda to this review, I would want to examine the Cloud Adoption Framework (CAF) by Amazon. It is not featured in the book, but does give the architect a proper handle on how to introduce the AWS stack into a company. CAF is advertised as a tool for helping organization understand how the transition to cloud solutions works, and what impact such an adoption has on the organization’s way of working. It acts as a fit/gap analysis checklist to determine and address gaps in skills, processes and tools. It helps the organization set goals and create work packages (called work streams in CAF) to achieve the target state for the organization. It also serves as a foundation for determining the business case for such an adoption, and which domains the gains needed to justify the adoptions are situated in. The CAF is structured around six focus areas, which are called perspectives and are divided into two categories: Business Capabilities and Technical Capabilities.
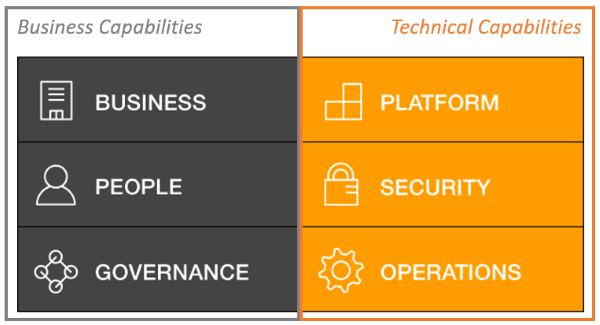
The Business Capabilities consist of three perspectives:
- Business Perspective: Focused on Value Realization. It assures that IT is aligned with business needs, and that IT investments can be mapped onto the business strategy as well as demonstrable business results. It becomes the main proponent for the business case and helps prioritize initiatives to achieve the adoption.
- People Perspective: Addresses the readiness of the organization for cloud adoption. In other words, it assesses organizational staff capability and change management processes for the adoption. It allows for an evaluation of organizational structures and roles and a determination of new skills and processes needed.
- Governance Perspective: This perspective deals with the prioritization and control of the initiatives towards cloud adoption. It aims to maximize business value of the IT investments and minimize business risks. This is typically done across Portfolio Management structures, as well as Program and Project Management. It even has extensions into Business Performance Management.
Likewise, the Technical Capabilities also have three perspectives:
- Platform Perspective: Focuses on applications and -infrastructure. The information gathered for this perspective can afterwards be incorporated in the architectural design for your solutions. This perspective comes with principles and implementation patterns, taking into account required computing power, network provisioning, storage provisioning, and database provisioning.
- Security Perspective: Organizes capabilities (IAM, detection, data protection, incident handling, and infrastructural security) that oversee the transformation of your organization’s security policies to include cloud adoption. Deals predominantly with risk and compliance.
- Operations Perspective: Every architect needs to think about designs that enable the operational side of any solution: operate, monitor, and recover in case of failure to a degree that is agreed upon by stakeholders (usually a cost versus risk/recovery speed debate). This perspective elaborates on the changes to current operational procedures and training needed.
The result of this fit/gap analysis is consolidated into an AWS CAF Action Plan, stipulating all the actions and work streams that need to be set up and executed for the adoption to be successful. More detailed information on the perspectives and on the creation of this action plan can be found on the Cloud Adoption Framework website.
| Review | SOA | EDA | BPM | ALM |